
Cara Mengatur Kembali Peta Situs XML Menggunakan Python
Pembicara Internet Marketing – Salah satu manfaat utama dari menggabungkan keterampilan pemrograman dan SEO adalah bahwa Anda dapat menemukan solusi cerdas yang akan sulit dilihat jika Anda hanya mengetahui SEO atau pemrograman secara terpisah.
Misalnya, melacak pengindeksan halaman terpenting Anda adalah tugas SEO yang krusial.
Jika mereka tidak diindeks, Anda perlu tahu alasannya dan mengambil tindakan. Bagian terbaiknya adalah kita dapat mempelajari semua ini secara gratis langsung dari Google Search Console.
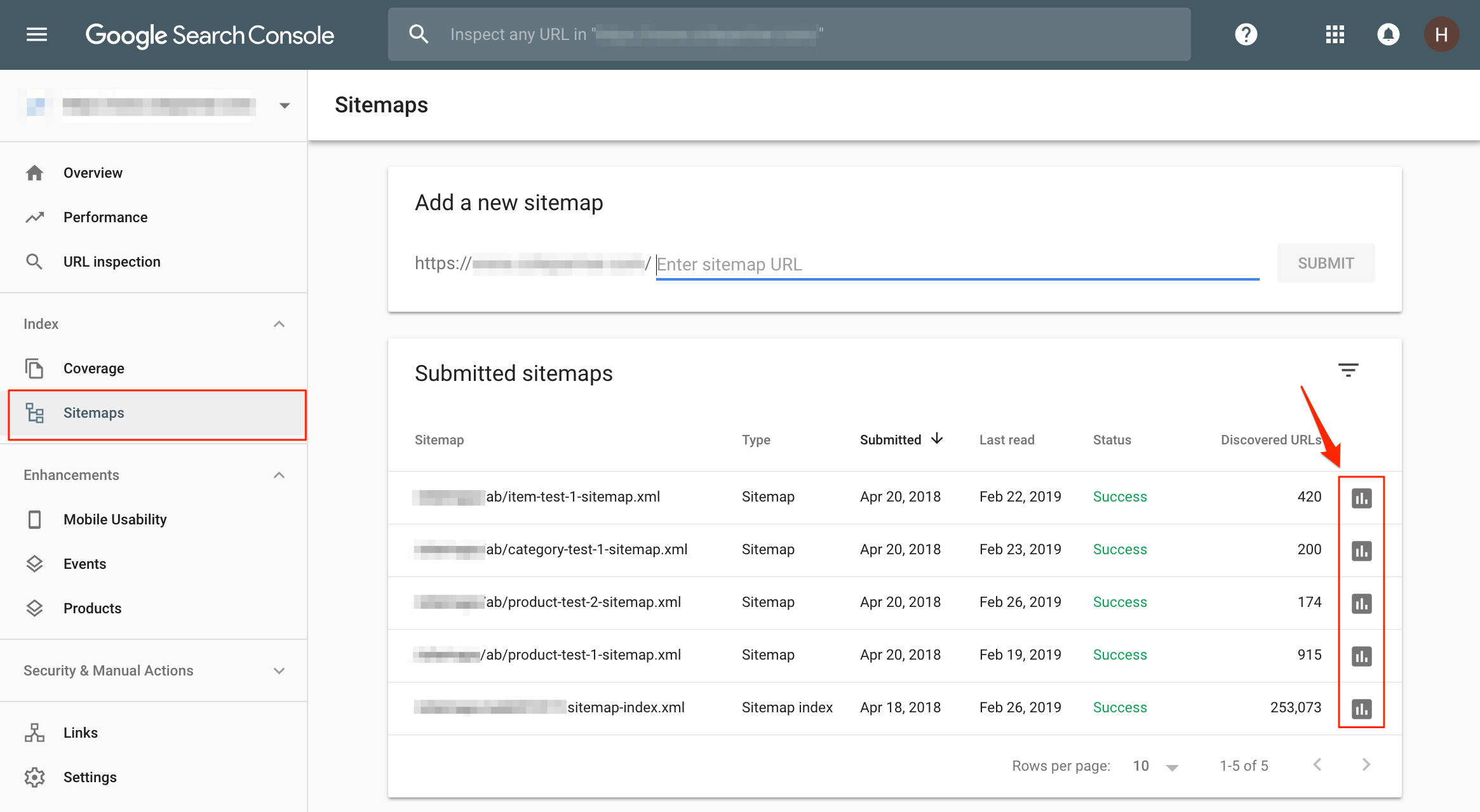
Pada tangkapan layar di atas, peta situs XML dikelompokkan berdasarkan jenis halaman, tetapi empat peta situs yang tercantum di sini secara khusus digunakan untuk melacak kemajuan beberapa pengujian A / B SEO yang kami jalankan untuk klien ini.
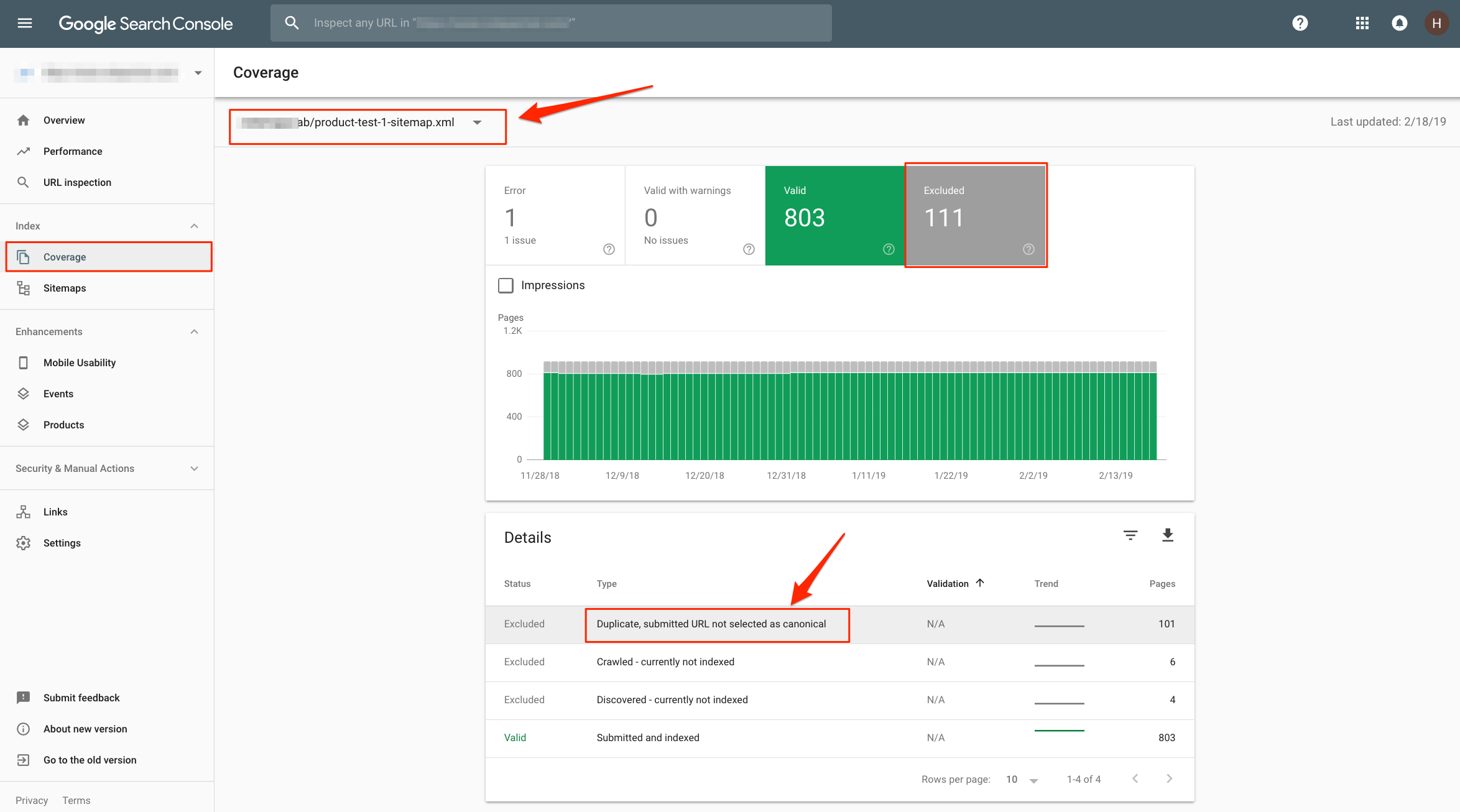
Dalam laporan Cakupan Indeks, kami dapat memeriksa setiap peta situs, mempelajari halaman mana yang tidak diindeks, mengapa halaman tersebut tidak diindeks, dan memahami cara memperbaikinya (jika dapat diperbaiki).
Sisa dari posting ini akan membahas bagaimana mengatur ulang peta situs XML Anda menggunakan kriteria apa pun yang dapat membantu Anda mengisolasi masalah pengindeksan pada halaman yang Anda pedulikan.
Daftar Isi
- Perpustakaan yang dibutuhkan
- Baca URL sitemap dari indeks sitemap XML
- Baca URL dari peta situs XML
- Mengatur ulang peta situs dengan kata-kata populer
- Membuat kata cloud
- Melanggar batas Cakupan Indeks URL 1k
- Mengatur kembali peta situs oleh buku terlaris
- Tulis peta situs XML
- Sumber daya untuk mempelajari lebih lanjut
Perpustakaan yang Diperlukan
Pada artikel ini, kita akan menggunakan Python 3 dan pustaka pihak ketiga berikut:
- BeautifulSoup
- Permintaan
- Panda : Nomor versi harus 0,23 atau lebih baru
- WordCloud
- Jinja2
- Nkt
Jika Anda menggunakan Google Colab, Anda perlu meningkatkan panda. Mengetik:
! pip instal –upgrade panda == 0.23
Proses keseluruhan
Kami akan membaca URL dari peta situs XML yang ada, memuatnya dalam bingkai data panda, membuat atau menggunakan kolom tambahan, mengelompokkan URL menurut kolom yang akan kami gunakan sebagai kriteria, dan menulis grup URL ke dalam peta situs XML.
Baca URL Peta Situs dari Indeks Peta Situs XML
Mari kita mulai dengan membaca daftar URL sitemap di indeks sitemapJournal Search Engine .
| sitemap_index_url = “ https://www.searchenginejournal.com/sitemap_index.xml “ | |
| dari bs4 import BeautifulSoup | |
| permintaan impor | |
| sitemap_index = {} | |
| r = requests.get (sitemap_index_url) | |
| xml = r.text | |
| sup = BeautifulSoup (xml) | |
| sitemapTags = soup.find_all ( “ sitemap “ ) | |
| print ( “ Jumlah peta situs adalah {0} “ .format ( len (sitemapTags))) | |
| untuk sitemap di sitemapTags: | |
| sitemap_index [sitemap.findNext ( “ loc “ ) .text] = sitemap.findNext ( “ lastmod “ ) .text | |
| cetak (sitemap_index) |
 oleh GitHub
oleh GitHubOutput parsial adalah:
Jumlah peta situs adalah 30
{‘https://www.searchenginejournal.com/post-sitemap1.xml’: ‘2005-08-15T10: 52: 01-04: 00’,…
Selanjutnya, kita memuatnya ke dalam bingkai data panda.
| impor panda sebagai pd | |
| print (pd. __version__ ) # harus 0,23 atau lebih baru | |
| df = pd.DataFrame.from_dict (peta situs, orient = “ index “ , kolom = [ ‘ lastmod ‘ ]) | |
| df.head ( 10 ) |
oleh GitHubOutput menunjukkan 10 URL pertama dengan stempel waktu modifikasi terakhir.
Baca URL dari Peta Situs XML
Sekarang kita memiliki URL sitemap, kita dapat menarik URL situs web yang sebenarnya. Sebagai contoh tujuan, kami hanya akan menarik URL dari peta situs pos.
| sitemaps = {} | |
| untuk (sitemap_url, lasmod) di sitemap_index.items (): | |
| if (sitemap_url.find ( “ post “ ) > 0 ): | |
| cetak (sitemap_url) | |
| jika 1 : # untuk pengujian | |
| r = requests.get (sitemap_url) | |
| xml = r.text | |
| sup = BeautifulSoup (xml) | |
| URLTags = soup.find_all ( “ url “ ) | |
| print ( “ Jumlah URL adalah {0} “ .format ( len (URLTags))) | |
| untuk URL di URLTags: | |
| sitemaps [ URL .findNext ( “ loc “ ) .text] = URL .findNext ( “ lastmod “ ) .text | |
| # print (xml_sitemap) # untuk pengujian | |
| # break #for testing |
oleh GitHubOutput parsial adalah
https://www.searchenginejournal.com/post-sitemap1.xml
Jumlah URL adalah 969
https://www.searchenginejournal.com/post-sitemap2.xml
Jumlah URL adalah 958
https://www.searchenginejournal.com/post-sitemap3.xml
Jumlah URL adalah 943
Mengatur Kembali Peta Situs dengan Kata-Kata Populer
Search Engine Journal Sitemap XML menggunakan plugin Yoast SEO, yang walaupun memisahkan kategori dan blog, semua posting dikelompokkan menjadi file sitemap post-sitemapX.xml.
Kami ingin mengatur ulang post sitemaps dengan kata-kata paling populer yang muncul di siput. Kami menciptakan kata cloud yang Anda lihat di atas dengan kata-kata paling populer yang kami temukan. Mari kita satukan ini!
Membuat Cloud Word
Untuk mengatur peta situs dengan URL paling populer, kami akan membuat kata cloud. Kata cloud hanya kata-kata paling populer yang dipesan berdasarkan frekuensinya. Kami menghilangkan kata-kata umum seperti “the”, “a”, dll. Untuk memiliki grup yang bersih.
Kami pertama-tama membuat kolom baru dengan hanya jalur URL, kemudian unduh bahasa Inggris dari paket Nltk.
| dari koleksi import Counter | |
| impor ulang | |
| impor nltk | |
| dari nltk.corpus import stopwords | |
| nltk.download ( ‘ stopwords ‘ ) | |
| dari urllib.parse impor urlparse | |
| df [ “ path “ ] = df.index.map ( lambda x : urlparse (x) .path) | |
oleh GitHubProsesnya adalah pertama-tama hanya mengambil bagian jalur URL, memecah kata-kata dengan menggunakan – atau / sebagai pemisah, dan menghitung frekuensi kata. Saat menghitung, kami mengecualikan kata berhenti dan kata-kata yang hanya digit. Pikirkan 5 di “5 cara untuk melakukan X”.
| cnt = Penghitung () | |
| english_stopwords = set (stopwords.words ( ‘ english ‘ )) | |
| untuk path di df.path: | |
| kata = re.split ( “ [- /] “ , path) | |
| untuk kata di kata: | |
| jika len (word) > 0 dan word tidak dalam english_stopwords dan bukan word.isdigit (): | |
| cnt [kata] + = 1 | |
| cnt.most_common ( 25 ) |
oleh GitHubOutput parsial adalah:
[( ‘google ‘, 4430), (‘pencarian’, 2961), (‘ seo ‘, 1482), (‘yahoo’, 1049), (‘pemasaran’, 989), (‘baru’, 919), ( ‘konten’, 919), (‘sosial’, 821),…
Hanya untuk bersenang-senang (seperti yang dijanjikan dalam tajuk utama), berikut adalah kode yang akan membuat cloud kata visual dengan frekuensi kata di atas.
| dari wordcloud, impor WordCloud, STOPWORDS , ImageColorGenerator | |
| impor matplotlib.pyplot sebagai plt | |
| word_cloud = [x [ 0 ] untuk x di cnt.most_common ( 25 )] | |
| word_cloud_obj = WordCloud ( max_words = 25 , background_color = “ white “ ) .hasilkan ( ” “ .join (word_cloud)) | |
| # word_cloud_obj = WordCloud (). menghasilkan (“” .join (word_cloud)) #default dengan latar belakang hitam jelek | |
| plt.imshow (word_cloud_obj, interpolasi = ‘ bilinear ‘ ) | |
| plt.axis ( “ off “ ) | |
| plt.show () |
oleh GitHubSekarang, kami menambahkan kolom wordcloud sebagai kategori ke bingkai data dengan URL sitemap.
| def get_category ( path ): | |
| kata = re.split ( “ [- /] “ , path) | |
| untuk kata di kata: | |
| jika kata di word_cloud: | |
| kembalikan kata | |
| kembalikan “ lainnya “ | |
| df [ ‘ category ‘ ] = df.path.apply (get_category) | |
| df.head () |
oleh GitHubBerikut ini hasilnya.
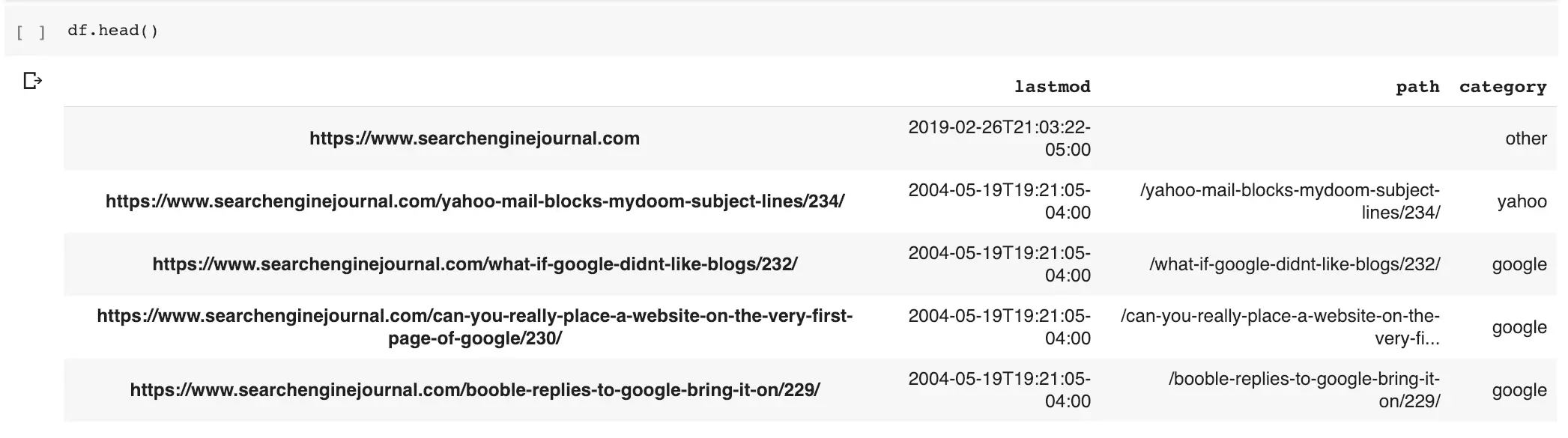
Kami dapat menggunakan kategori baru ini untuk meninjau URL yang berisi kata populer: Google.
df [df [“category”] == “google”]
Daftar ini hanya URL dengan kata populer di jalurnya.
Melanggar Batas Cakupan Indeks 1k URL
Laporan Cakupan Indeks Google Search Console sangat kuat, tetapi membatasi laporan hanya untuk seribu URL. Kami dapat membagi URL sitemaps XML kami yang sudah difilter lebih jauh menjadi grup-grup dengan 1k URL.
Kita dapat menggunakan kemampuan pengindeksan panda yang kuat untuk ini.
| google_df = df [df [ “ kategori “ ] == “ google “ ] | |
| first = google_df [: 1000 ] | |
| second = google_df [ 1000 : 2000 ] | |
| third = google_df [ 2000 : 3000 ] | |
| last = google_df [ 3000 :] | |
oleh GitHubReorganisasi Peta Situs oleh Bestsellers
Salah satu kegunaan paling kuat dari teknik ini adalah untuk memecah halaman yang mengarah pada konversi.
Di situs e-niaga, kami dapat membuka penjual terbaik dan mempelajari mana yang tidak diindeks. Uang mudah!
Karena SEJ bukan situs transaksional, saya akan membuat beberapa transaksi palsu untuk menggambarkan taktik ini. Biasanya, Anda akan mengambil data ini dari Google Analytics.
| high_value_pages = df [df.path.str.contains ( “ adwords | facebook | ads | media “ , regex = True )] | |
| impor numpy sebagai np | |
| high_value_pages [ “ fake_transactions “ ] = np.random.randint ( 1 , 200 , high_value_pages.shape [ 0 ]) | |
| high_value_pages = high_value_pages.reset_index () | |
| fake_transaction_pages = high_value_pages [[ “ path “ , “ fake_transactions “ ]] | |
| fake_transaction_pages.head () |
oleh GitHubSaya berasumsi bahwa halaman-halaman dengan kata-kata “adwords”, “facebook”, “ads” atau “media” memiliki transaksi.
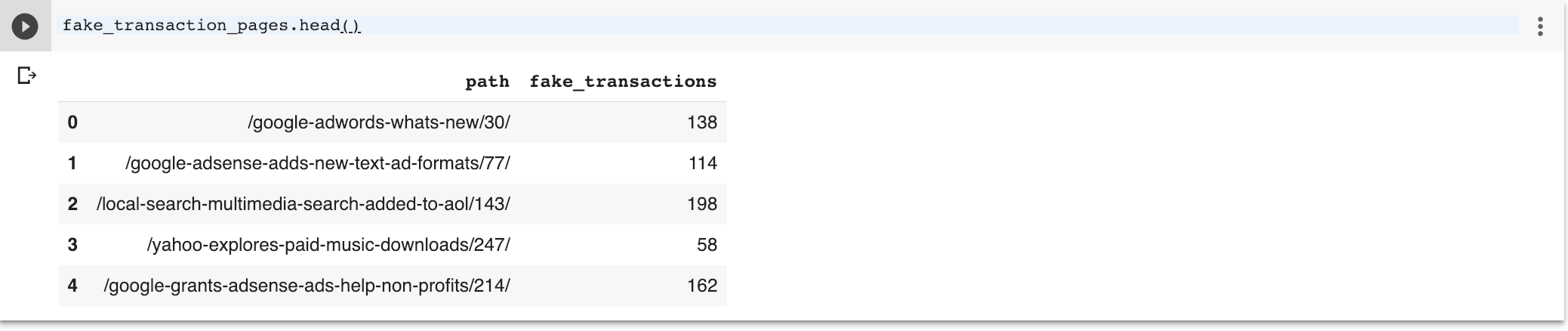
Kami membuat kolom transaksi palsu dengan hanya jalur relatif seperti yang biasa Anda temukan di Google Analytics.
Selanjutnya, kita akan menggabungkan dua frame data untuk menambahkan data transaksi ke bingkai data sitemap asli. Secara default, fungsi panda merger akan melakukan gabungan dalam, jadi hanya baris yang umum tersedia.
df.merge (fake_transaction_pages, left_on = ”path”, right_on = ”path”)
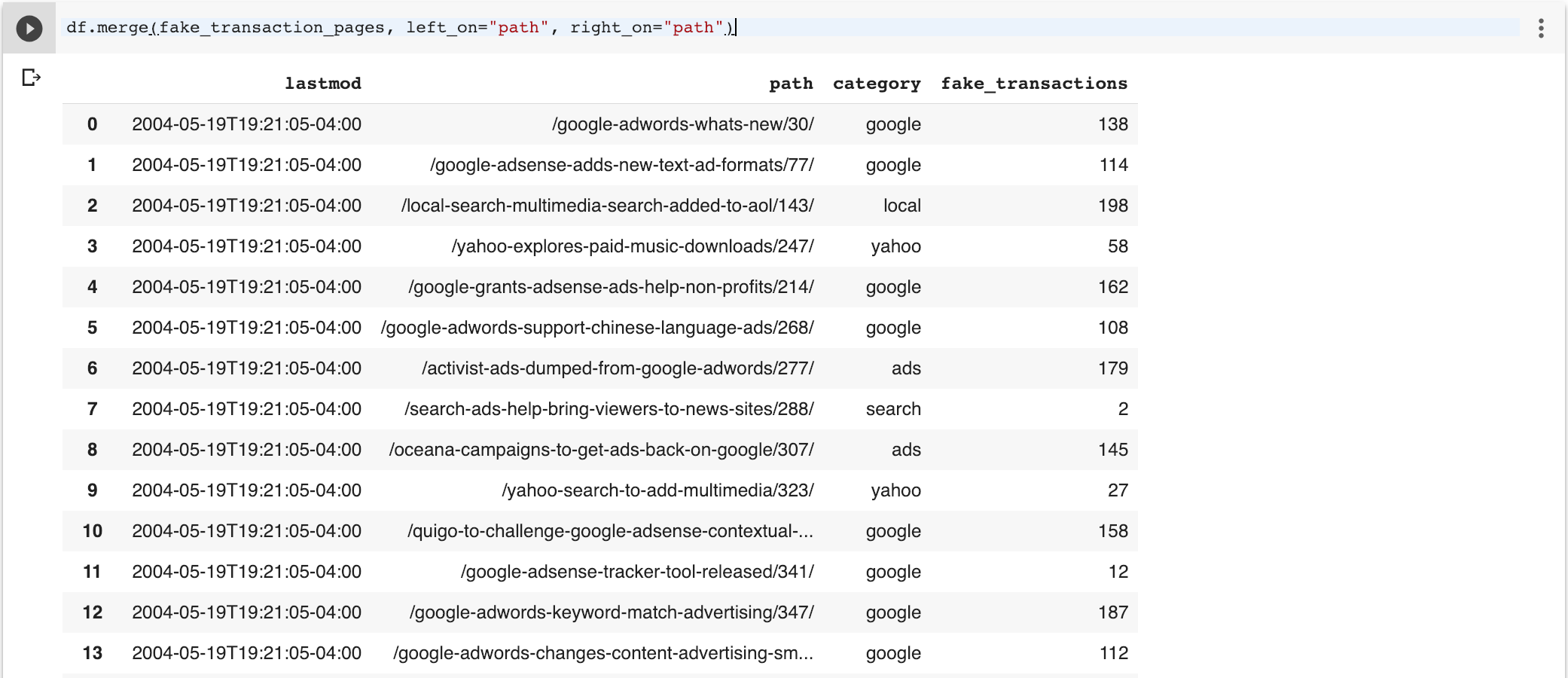
Karena saya ingin semua baris, saya akan mengubah tipe gabungan ke kiri sehingga mencakup semua baris dalam bingkai data asli. Perhatikan baris yang hilang NaN palsu (nilai yang hilang) di kolom transaksi palsu.
df.merge (fake_transaction_pages, left_on = ”path”, right_on = ”path”, how = ”left”)
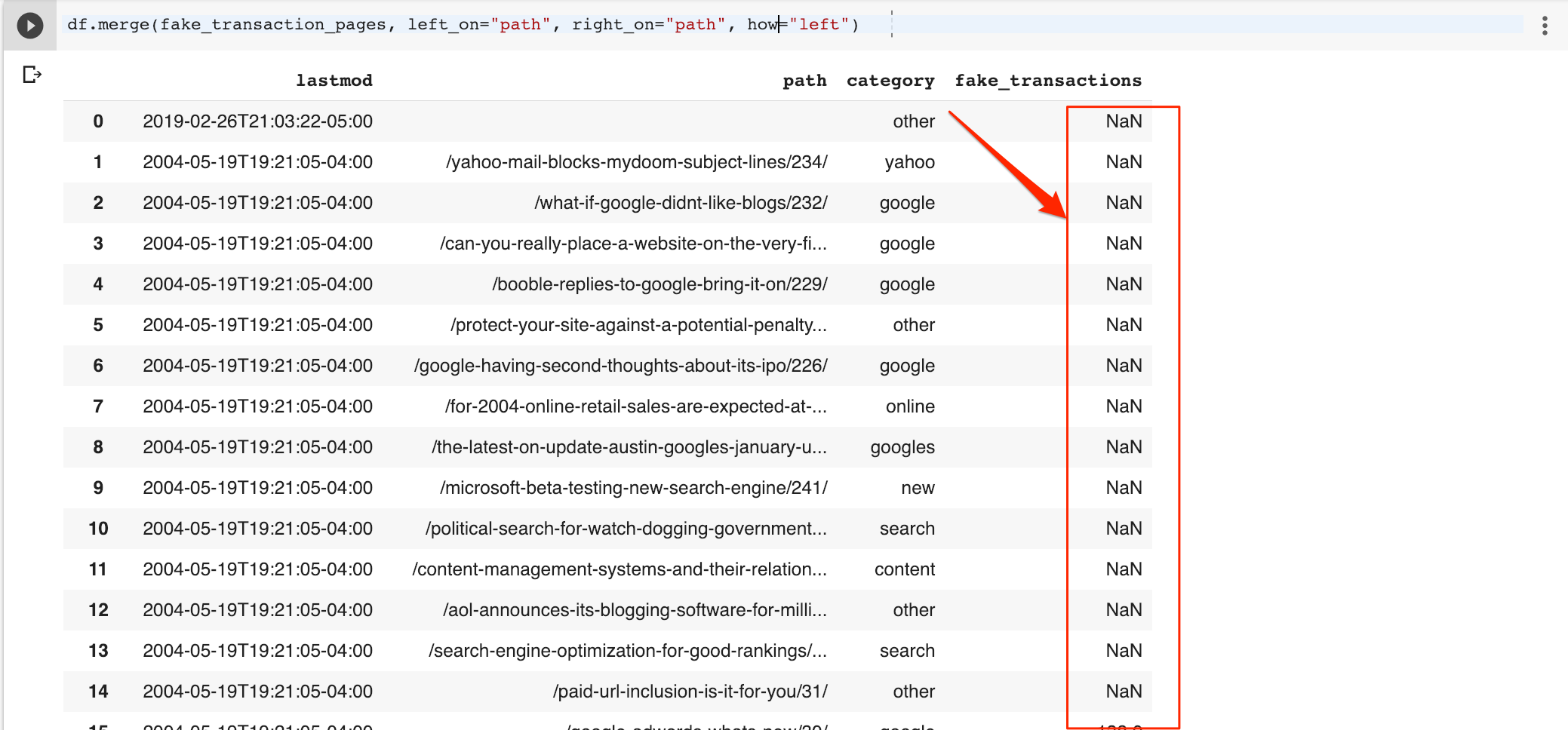
Saya dapat dengan mudah mengisi nilai yang hilang dengan nol.
df.merge (fake_transaction_pages, left_on = ”path”, right_on = ”path”, how = ”left”) .fillna (0)
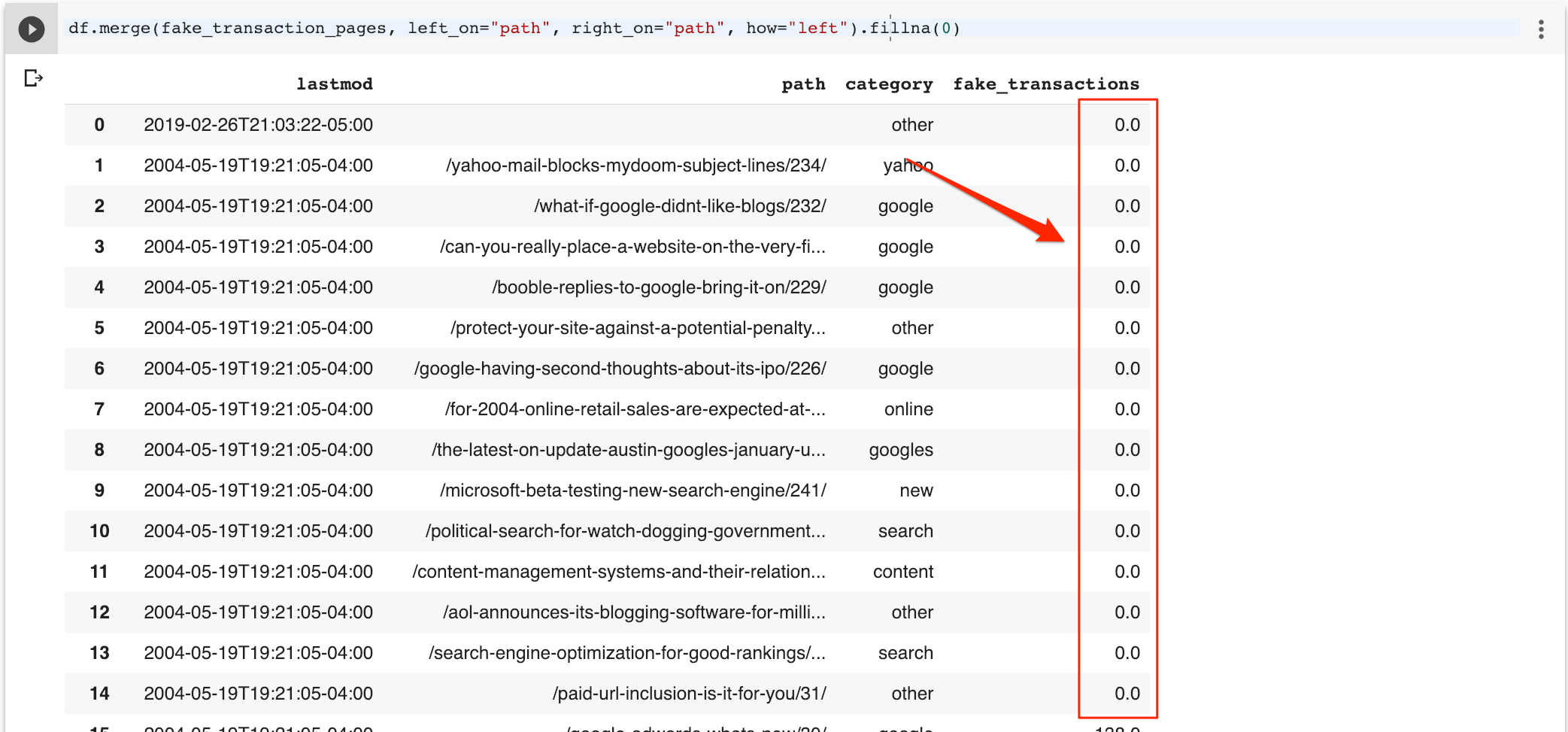
Saya sekarang bisa mendapatkan daftar penjual terbaik (berdasarkan transaksi) menggunakan ini.
new_df = df.merge (fake_transaction_pages, left_on = “path”, right_on = “path”, how = “left”). fillna (0)
new_df [new_df.fake_transactions> 0]
Tulis Peta Situs XML
Sejauh ini, kami telah melihat cara mengelompokkan URL menggunakan bingkai data panda menggunakan kriteria yang berbeda, tetapi bagaimana kami mengubah URL ini kembali menjadi peta situs XML? Cukup mudah!
Selalu ada cara yang sulit untuk melakukan hal-hal dan ketika datang untuk membuat peta situs XML yang akan menggunakan BeautifulSoup, lxml atau perpustakaan serupa untuk membangun pohon XML dari awal.
Pendekatan yang lebih sederhana adalah dengan menggunakan bahasa templating seperti yang digunakan untuk membangun aplikasi web. Dalam kasus kami, kami akan menggunakan bahasa templat populer yang disebut Jinja2 .
| dari Templat impor jinja2 | |
| sitemap_template = “” “ <? xml version =” 1.0 “encoding =” UTF-8 “?> | |
| <urlset xmlns = “http://www.sitemaps.org/schemas/sitemap/0.9”> | |
| {% untuk halaman dalam halaman%} | |
| <url> | |
| <loc> {{halaman [0] | safe}} </loc> | |
| <lastmod> {{halaman [1]}} </lastmod> | |
| </url> | |
| {% endfor%} | |
| </urlset> “” “ | |
| template = Templat (sitemap_template) | |
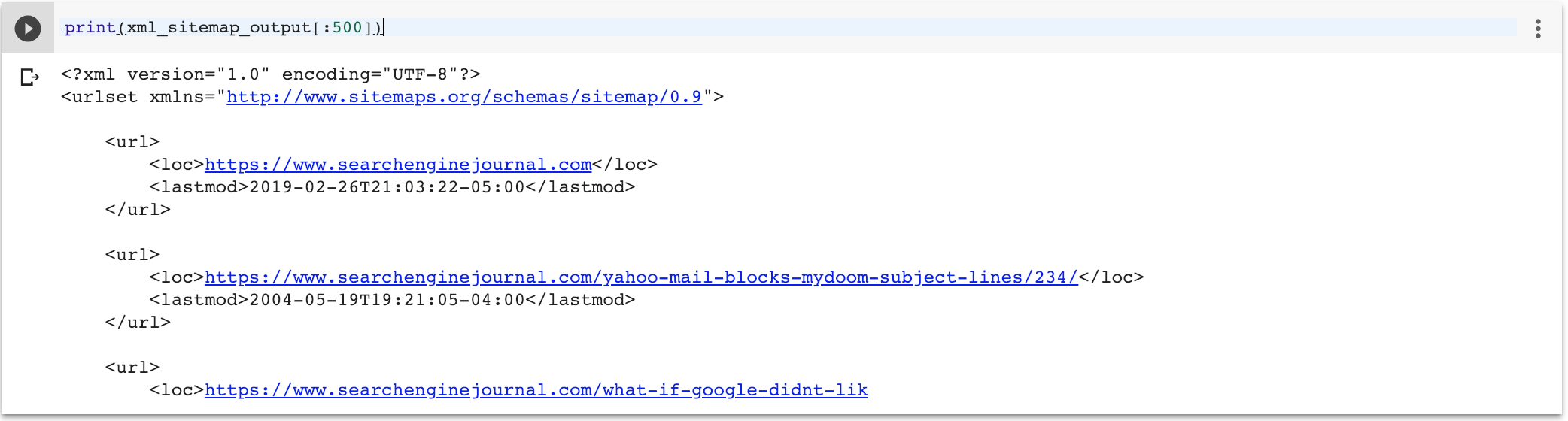
| xml_sitemap_output = template.render ( halaman = df.itertuples ()) | |
| print (xml_sitemap_output [: 500 ]) | |
oleh GitHubAda tiga komponen di sini:
- Templat dengan for loop untuk beralih dari objek konteks yang disebut halaman. Seharusnya tuple Python, di mana elemen pertama adalah URL, dan yang kedua adalah timestamp modifikasi terakhir.
- Kerangka data panda asli kami memiliki satu indeks (URL) dan satu kolom (cap waktu). Kita dapat memanggil panda itertuples () yang akan membuat urutan yang akan dirender dengan baik sebagai peta situs XML.
Ini setidaknya 10 kali lebih sederhana daripada membangun peta situs dari awal!